Before we dive into how to handle this shadow root element, let us try to understand what it is first.
Shadow DOM:
- Shadow DOM is a functionality to bind DOM elements without putting them into the main DOM tree.
- In simple words, it is a layer present over the main DOM.
- This creates a barrier for testers to access the elements within the shadow root.
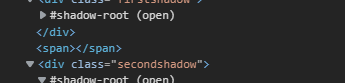
- This is how a shadow root looks. Any XPath or CSS won't work with this.
- The idea is to achieve encapsulation on the HTML level and avoid disturbing the other part of the code.
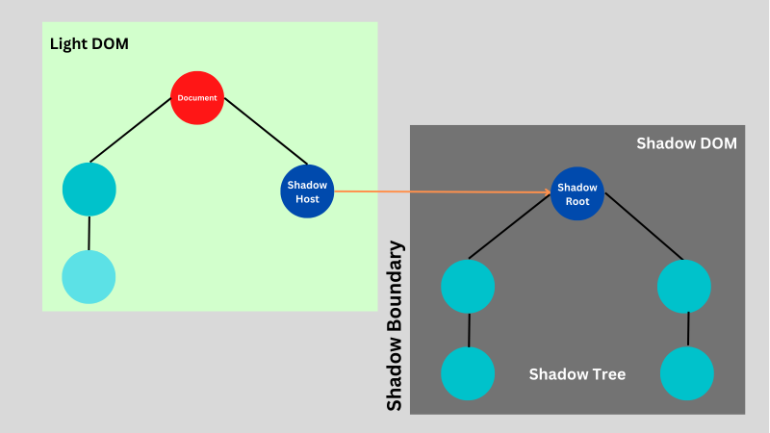
- Here we can see the shadow host, where the shadow root is present and is attached to the DOM.
- This is how the shadow tree is bound inside.
- The Shadow boundary is where the Shadow DOM ends, and the regular DOM begins.
In this article, we will get a text from this autopract site covered in a shadow root.

- We are going to use three different techniques and an easy way to do this.
1.) Using The Browser Console
- Let us try to get the selector for the text "Shadow Element 1-1" from the autopract site.
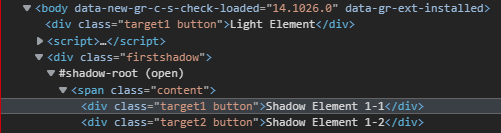
This is how it looks: go to the console in the same browser and type it in.
const ele = document.querySelector('.firstshadow')
ele.shadowRoot.querySelector('.target1')- Using the queryselector, we accessed the class just above the shadow boundary and using the shadowRoot method, we got into the Shadow DOM and accessed the class of our required text simple right.
document.querySelector('.firstshadow').shadowRoot.querySelector('.target1')It can also be written like this.
package week4.day2;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import io.github.bonigarcia.wdm.WebDriverManager;
public class Point {
public static void main(String[] args) {
WebDriverManager.chromedriver().setup();
ChromeDriver driver = new ChromeDriver();
driver.get("http://autopract.com/selenium/shadowdom1/");
driver.manage().window().maximize();
String str = "return document.querySelector('.firstshadow').shadowRoot.querySelector('.target1')";
WebElement text = (WebElement) driver.executeScript(str);
String fString = text.getText();
System.out.println(fString);
}
}

- Store the select with the return, or it will throw undefined in a string.
- Using executeScript, pass in the str object as it will execute the process.
- Now with the simple selenium method of getting text, we can finish our job efficiently by fetching it.
2.)Using JS Path Copy
- Let us try to retrieve the text "Shadow Element 2-2".
- Locate it in the element DOM and right-click -> copy -> copy JS path.
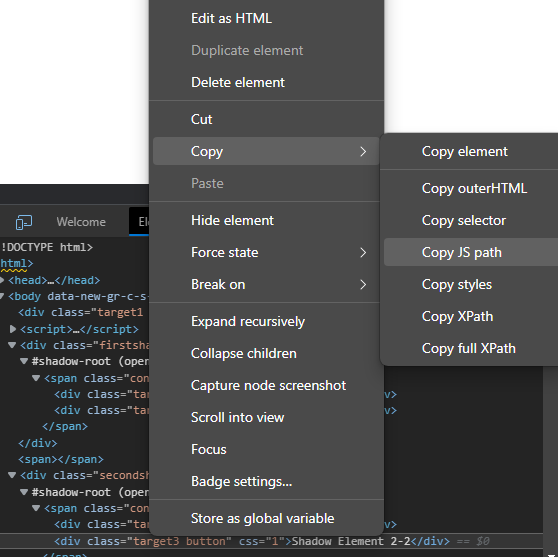
- Instead of writing queryselector, we can copy the path.
document.querySelector("body > div.secondshadow").shadowRoot.querySelector("span > div.target3.button")
This is the copied JS path.
String str = "return document.querySelector(\"body > div.secondshadow\").shadowRoot.querySelector(\"span > div.target3.button\")";
WebElement text = (WebElement) driver.executeScript(str);
String fString = text.getText();
System.out.println(fString);
Repeat the same process as before.3.)Using A Plugin
- There is a unique plugin for this called shadow automation selenium.
- Download the plugin from here and download jar maven or Gradle from here.
package week4.day2;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import io.github.bonigarcia.wdm.WebDriverManager;
public class Point {
public static void main(String[] args) {
WebDriverManager.chromedriver().setup();
ChromeDriver driver = new ChromeDriver();
driver.get("http://autopract.com/selenium/shadowdom1/");
driver.manage().window().maximize();
Shadow sh = new Shadow(driver);
WebElement ele = sh.findElement("div[class='target3 button']");
String text = ele.getText();
System.out.println(text);
}}
- Initialize Shadow, i.e., the plugin, and pass in the driver as cast.
- Using a normal XPath or CSS selector, we can get the text without a queryselector.
- Log in to post comments