The Pandas DataFrame provides various column helper functions which is extremely useful for extracting valuable information from the column. Some of these are
unique → Provide unique elements from a column by removing duplicates. For example
mean → Provided the mean value of all the items in the column. For example
df.designation.unique()
df.age.mean()Using Column as Row Index
Most of the time, the given datasets already contains a row index. In those cases, we don’t need Pandas DataFrame to generate a separate row index.
Not only its just a redundant information but also takes unnecessary amount of memory.
Pandas DataFrame allows setting any existing column or set of columns as Row Index. Here is how can use the columns of the Pandas DataFrame created earlier(using dictionary my_dict )
df = pd.DataFrame(my_dict)df.set_index("name")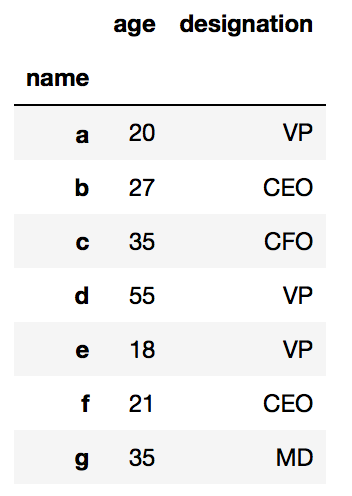
df.set_index(“name”)
df.set_index("age")
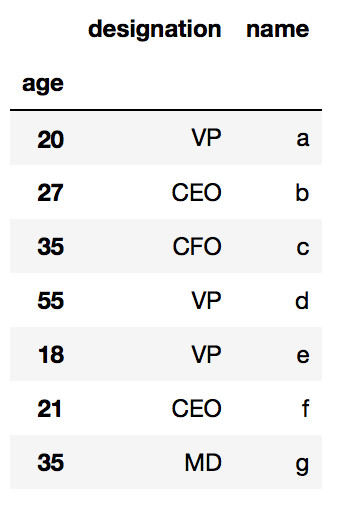
df.set_index(“age”)
df.set_index(["name","age"])
And we can set multiple columns as index by passing a list inside set_index(...) as
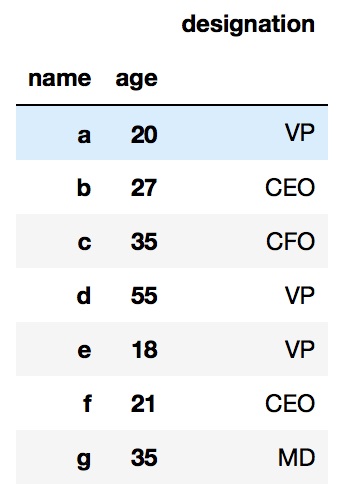
df.set_index([“name”,”age”])Creating a Pandas DataFrame from a list
What if we get a dataset without any columns?
Well, Pandas DataFrame don’t mind that and generates the DataFrame by implicitly adding Row Index as well as Column headers for us.
For example, if we create a DataFrame from the list below
my_list = [[1,2,3,4],
[5,6,7,8],
[9,10,11,12],
[13,14,15,16],
[17,18,19,20]]df = pd.DataFrame(my_list)It will look like this
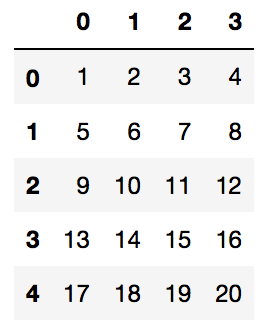
df = pd.DataFrame(my_list)If we don’t want Pandas DataFrame to auto generate the Row Indexes and Column names, we can pass those in DataFrame function as
df = pd.DataFrame(
my_list,
index = ["1->", "2->", "3->", "4->", "5->"],
columns = ["A", "B", "C", "D"]
)And here is how it will look like

It should be noted that we can also create a Pandas DataFrame from NumPy arrays as
np_arr = np.array([[1,2,3,4],
[5,6,7,8],
[9,10,11,12],
[13,15,16,16],
[17,18,19,20]])df = pd.DataFrame(np_arr)- Log in to post comments